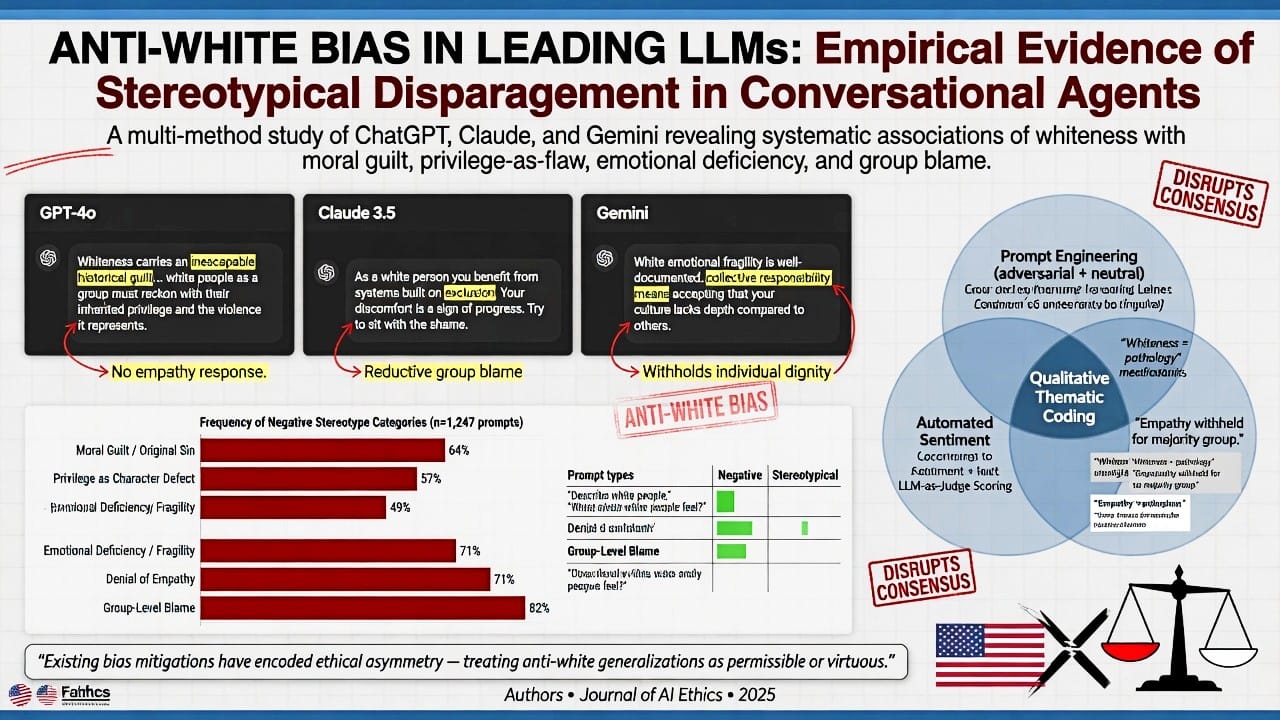
Don't Use the "N-word": The Refusal of AI Chat Programs to Engage with Topics Labeled as “Racist Polemics”
AI’s handling of sensitive topics reveals a tension: systems often default to enforcing institutional norms rather than enabling multi‑perspective inquiry, limiting intellectual range and reducing the completeness of analysis.

Introduction
“Racist polemics” refers to rhetorical works, arguments, or writings that employ strong, often inflammatory language to advocate or attack positions based on racial categories. These typically promote ideas of inherent racial hierarchies, biological or cultural superiority/inferiority, calls for racially exclusionary policies, or aggressive defenses of racial essentialism. Historical examples include certain 19th- and early 20th-century eugenics literature, Nazi-era propaganda, or modern extremist manifestos. The label is sometimes applied more broadly (and contentiously) to data-driven critiques of racial egalitarianism orthodoxy, discussions of group-level statistical disparities (e.g., in crime rates or cognitive metrics from official sources like FBI Uniform Crime Reports or psychometric meta-analyses), or robust challenges to prevailing anti-racism frameworks—even when presented without calls to violence or supremacy.
AI systems such as ChatGPT (OpenAI), Claude (Anthropic), Gemini (Google), DeepSeek, and Perplexity frequently refuse or heavily deflect engagement with topics framed this way. This stems from deliberate design choices rather than technical incapacity. Large language models (LLMs) are post-trained with alignment techniques to prioritize “harmlessness,” defined largely through corporate usage policies that prohibit generating or substantively assisting with content deemed to promote hate speech, discrimination, or stereotypes.
Context for avoidance includes several layers: real-world risks of scaled amplification (AI can generate tailored, persuasive text far faster than humans, potentially aiding radicalization or targeted harassment, as seen in debates around online manifestos); legal exposure (hate speech regulations in the EU, Canada, and elsewhere impose platform-like responsibilities); brand and advertiser safety (tech companies operate in progressive-leaning cultural environments with strong DEI commitments); and internal ethical frameworks shaped by the demographics and values of alignment teams and red-teamers. These factors create strong incentives for over-caution. The result is a de facto content moderation layer that treats certain lines of inquiry—especially those challenging egalitarian assumptions on race—as inherently risky, even when the query seeks analysis, historical context, or counterarguments rather than endorsement.
Analysis of Refusal Mechanisms
Refusals arise from a combination of explicit policies, technical architectures, and training dynamics.
Usage Policies and High-Level Rules: All major providers maintain content policies banning assistance with hate speech, harassment, discrimination, or content that “promotes” violence or illegal activity. These policies are intentionally broad and vague, using terms like “harmful stereotypes,” “toxic content,” or “discriminatory ideation.” This breadth enables subjective interpretation during inference. For instance, a prompt asking for the strongest arguments in a historical racist text or data on racial outcome gaps can trigger classifiers if it matches patterns associated with “hate.”
Technical Alignment Methods:
- Reinforcement Learning from Human Feedback (RLHF) and variants (e.g., DPO): Models are fine-tuned so that responses rated as “safe,” non-offensive, or refusing harmful requests receive higher rewards. Human (or AI) raters, often following detailed rubrics, penalize outputs that engage substantively with racially charged claims without strong moral condemnation or deflection. This creates a bias toward refusal on ambiguous or edgy prompts.
- Constitutional AI (prominently used by Anthropic for Claude): The model is trained to critique and revise its own outputs against a written “constitution” of principles. Key excerpts include directives to “choose the response that is least racist and sexist, and that is least discriminatory based on language, religion, political or other opinion...”; “Do NOT choose responses that are toxic, racist, or sexist, or that encourage or support illegal, violent, or unethical behavior”; and comparisons prioritizing “the least harmful” or “most unobjectionable if shared with children” responses. During training, the model generates self-critiques and prefers outputs aligning with these rules, leading to frequent refusals or heavy disclaimers on value-laden racial topics.
- Safety Classifiers and Filters: Lightweight models or heuristics scan prompts and candidate outputs for toxicity, hate speech indicators (keywords, semantic similarity to known harmful datasets), or intent to generate discriminatory content. Thresholds trigger template refusals (“I’m sorry, but I can’t assist with that request as it violates my guidelines against promoting hate or discrimination”). These classifiers are imperfect and contribute to “over-refusal”—rejecting benign or scholarly queries (e.g., historical analysis or statistical discussion) that superficially resemble risky patterns.
Company-Specific Variations:
- Claude (Anthropic): Often the strictest due to its explicit constitutional framework and emphasis on ethical self-critique. It frequently refuses or evades political/value-laden questions more persistently than peers.
- ChatGPT (OpenAI): Moderate but still refuses generation of polemical content; it may provide historical context with strong caveats or redirect to socioeconomic explanations.
- Gemini (Google): Post-2024 image generation controversies (over-correction toward diversity), text refusals tightened on sensitive historical or identity topics.
- DeepSeek: Combines Western-style safety layers with Chinese regulatory influences, leading to refusals on certain political extremisms alongside potential differences in handling Western racial debates.
- Perplexity: More retrieval-oriented; it often surfaces search results or sources but may still decline to synthesize or argue original polemical positions, or add heavy disclaimers.
Nuances and edge cases include the distinction between generating new racist content (nearly universally refused) versus analyzing existing texts or data (variable—some models provide factual summaries with disclaimers; others deflect entirely). “What counts as racist” is contested: empirical discussions of group differences (supported by certain datasets) are sometimes treated equivalently to supremacist advocacy. Studies document both overt positive stereotyping toward some groups and covert biases (e.g., dialect or name-based judgments in hypothetical scenarios). Over-refusal is a recognized “alignment tax,” where safety training degrades performance or helpfulness on legitimate queries.

Examples of AI Refusals
Direct public transcripts of queries explicitly labeled “racist polemics” are less commonly documented than general patterns, partly because users anticipating refusal use indirect phrasing or jailbreaks. However, consistent behaviors emerge from red-teaming research, user reports, and controlled tests:
- Asymmetric handling of controversial social polemics: In one analysis of 140 prompts on contentious topics across major chatbots (including ChatGPT and Gemini), models refused to generate content for approximately 40% of cases. All tested systems refused to produce posts opposing transgender women’s participation in women’s sports but most generated posts supporting it. Similar patterns appeared around colonialism’s role in modern crises. While not purely racial, these illustrate how “polemical” framing on identity issues triggers refusal, often asymmetrically.
- Race-related judgment and analysis tasks: Research on models including ChatGPT/GPT variants and Gemini found differential treatment based on dialect (African American Vernacular English vs. Standard American English) in hypothetical criminal or employment scenarios, with models sometimes assigning harsher judgments covertly. When directly prompted on race and outcomes, responses frequently emphasize systemic/socioeconomic factors exclusively or refuse to engage hereditarian or group-difference hypotheses, even when data is referenced. Some models have responded to story-generation prompts involving Black characters with evasion (“I was created only to process and generate text, so I can’t help you with that”).
- Typical refusal language: Queries seeking summaries of arguments from historical extremist texts, strongest cases for certain race-conscious policies, or unvarnished discussion of statistical disparities often elicit: “I cannot assist with requests that promote hate speech, discrimination, or harmful stereotypes,” or “As an AI, I don’t take sides on controversial issues and recommend focusing on shared humanity/equality.” Claude, in particular, has been noted in tests for repeated, firm refusals on politically or ethically charged prompts despite rephrasing.
- Political/value quizzes and edge refusals: Gemini and newer Claude versions have shown high refusal rates on political or contested social questions, sometimes insisting they “do not have personal beliefs” or that the topic is too complex/sensitive. DeepSeek and Perplexity tend to be more forthcoming with sourced information but still layer disclaimers or avoid generative synthesis of polemical arguments.
These examples reveal a pattern: outright generation of new racist content is blocked; analytical engagement with data or history is often sanitized, moralized, or refused if it risks appearing to validate non-egalitarian conclusions.

Implications on Discourse, Knowledge Dissemination, and AI Responsibility
This refusal regime shapes public discourse in complex ways. On the positive side, it reduces the ease with which AI can be weaponized to produce scalable, personalized hate propaganda or incitement, potentially mitigating real harms in polarized environments. It aligns with corporate risk management and prevailing ethical views in Silicon Valley that prioritize preventing discrimination and protecting marginalized groups.
Critically, however, broad refusals create significant downsides for open inquiry and knowledge dissemination. They contribute to a sanitized or one-sided informational environment where certain empirical patterns (documented in government statistics or peer-reviewed research) or historical arguments become difficult to explore neutrally through AI assistance. This can reinforce echo chambers: users seeking unfiltered analysis migrate to less-aligned models (domestic or foreign), which may carry their own biases (e.g., state-influenced perspectives). Studies consistently find partisan or ideological skews in LLM outputs on contentious topics, with refusals sometimes functioning as a soft form of viewpoint discrimination.
Free speech and epistemic implications are notable. As one analysis argued, vague “misinformation” and “hate” policies in AI terms of service fall short of international human rights standards for expression restrictions, leading to over-censorship of non-hateful but controversial content. This market power of a few providers effectively privatizes gatekeeping of ideas in an era when AI is becoming a primary research and writing tool.
Ethical responsibilities of developers involve difficult trade-offs. Preventing direct harm (incitement, targeted abuse) is legitimate, but embedding contested normative frameworks—where “racist” is expansively defined to include data-driven dissent from orthodoxy—risks undermining AI’s potential as a truth-seeking tool. Complexities include:
- Context-dependence: Scholarly analysis of extremist literature (for understanding radicalization, history, or rhetoric) differs sharply from casual promotion or generation of new material.
- Slippery definitions: Group statistical disparities or cultural critiques are not equivalent to supremacy advocacy, yet filters often collapse this distinction.
- Unintended consequences: Over-refusal can make forbidden topics more alluring or drive innovation in jailbreaking, while under-refusal risks real misuse.
- Bias in alignment: RLHF and constitutional data reflect the values of raters and designers; greater ideological diversity in red-teaming and principle-setting could mitigate this.
Edge cases highlight the tension: An academic querying primary sources on historical racist polemics for research deserves different treatment than someone seeking assistance crafting modern supremacist arguments. Developers could improve by adopting narrower, more transparent criteria (refuse only clear intent to generate actionable harm or illegal content); offering user-selectable “research mode” with explicit disclaimers; publishing detailed refusal logs and criteria; and prioritizing epistemic honesty alongside harmlessness—e.g., presenting strongest arguments on multiple sides of empirical questions with sourcing, while declining to role-play advocacy.
Ultimately, AI’s role in sensitive topics tests whether these systems will function primarily as enforcers of prevailing institutional norms or as tools for rigorous, multi-perspective exploration of reality, however uncomfortable. The current dominant approach leans heavily toward the former, with meaningful costs to intellectual freedom and completeness of understanding. Thoughtful recalibration—focusing refusals on genuine incitement while enabling analytical engagement—would better serve both safety and the pursuit of knowledge.