Spatio-Temporal Co-Optimization of Power Delivery and Heat Removal in AI Data Centers
Hyperscale AI data centers face a hidden crisis: synchronized GPU workloads create extreme power spikes and heat surges that conventional infrastructure cannot easily absorb. This report examines the physics, bottlenecks, failure modes, and future solutions shaping AI’s real scalability limits. now.
Abstract
Modern AI data centers confront an unprecedented multi-layer engineering challenge. They host dense clusters of synchronized GPUs drawing tens of megawatts of power, while generating correspondingly extreme heat fluxes. This paper analyzes the co-optimization of grid-level power delivery and chip-level cooling under non-stationary, synchronization-heavy GPU workloads. We model the data center as a tightly-coupled hierarchy spanning utility transmission, facility electrical distribution, rack-level power and cooling loops, and chip-scale thermal interfaces. We show that AI workloads impose “distinct” loads with high power density (30–100+ kW/rack) and burstiness (hundreds of MW swings in seconds), straining each layer of the infrastructure. These interactions are fundamentally nonlinear: doubling compute hardware more than doubles power and heat demands, forcing exponential growth in infrastructure capacity. Unlike classical clouds, AI clusters suffer severe power spikes and thermal bottlenecks that software cannot eliminate. We identify failure modes (voltage sags, equipment stress, thermal runaway, water limits) and show that solving this problem requires innovations across physics domains and system boundaries. We conclude with research directions (e.g. physics-informed control, advanced cooling materials, smart grid integration) to address what is arguably the most intractable engineering problem in AI infrastructure.
Problem Statement
AI-driven hyperscale data centers must simultaneously satisfy grid-scale power delivery and chip-scale cooling for tightly synchronized GPU clusters. These clusters exhibit highly dynamic, synchronous power draws: GPUs process tensor operations in lockstep, causing step-like load changes every few seconds. The result is extreme spatio-temporal fluctuations: at the grid level, rapid multi-megawatt swings; at the rack level, load swings of 0%–150% of rated power; and at the chip level, thermal transients of tens of °C within seconds. The infrastructure must feed these bursts without collapse, remove the attendant heat without throttling, and do so with minimal latency. This co-optimization problem spans electricity network physics (transformers, converters, wiring inductance), facility power topology (PDUs, UPS, busway), cooling loops (chillers, CDU units, heat exchangers), and thermodynamics (chip cooling, liquid flow, heat transfer), all under the timing of AI workloads.
This joint coupling is deeply intractable. Traditional data center design assumes load diversity and steady growth, but modern AI workloads violate those assumptions. We argue this is the single most challenging problem in AI infrastructure engineering, because solutions must operate across domains: boosting grid capacity and managing electrical transients, upgrading facility hardware, and innovating at the chip cooling interface – none of which can be solved by software scheduling alone. The challenge is worsened by timing misalignments: power grids evolve on slow timescales (months/years), while GPU clusters swing on millisecond scales. In short, we must architect an end-to-end solution where the physics of electricity and thermodynamics fundamentally limit performance.
Background
AI data centers are emerging as a distinct load category. Unlike conventional cloud workloads, they feature very high power density and rapid variability. For example, a single ChatGPT-style inference consumes ~2.9 Wh – nearly ten times a typical web search. A conventional data center rack (7–10 kW) is dwarfed by an AI rack routinely running at 30–100 kW. Rack-power budgets that were once in the single digits now reach hundreds of kilowatts in AI factories. In practice, liquid-cooled GPU cabinets can pack 288 GPUs at 60 kW per rack, and latest architectures can spike to >150 kW momentarily. Industry surveys confirm that “predictable growth curves” are obsolete: roughly half of data center operators already hit power limits when trying to deploy new AI clusters.
Concurrently, cooling demands have skyrocketed. AI-accelerated servers generate ~5× the heat of a CPU server in the same space. Racks routinely exceed traditional cooling capacities: densities above 40 kW are becoming baseline for AI, with 100 kW+ per rack projected. Air-cooling now often gives way to liquid solutions (direct-to-chip cold plates, rear-door heat exchangers, immersion) as the primary tactic. Research into novel cooling (e.g. hierarchical thin-film evaporators) is motivated by these extraordinary heat fluxes.
In short, AI DCs are power-hungry, heat-intensive, and erratic compared to classical centers. Multiple surveys and studies emphasize this shift. Hyperscale AI sites now draw many hundreds of megawatts – on par with small cities – and concentrate in a few regions (e.g. Virginia, Texas) that strain local grids. These facts underscore why legacy engineering models must be rethought.
System Model
We model the AI data center as a hierarchical ecology of interacting layers.
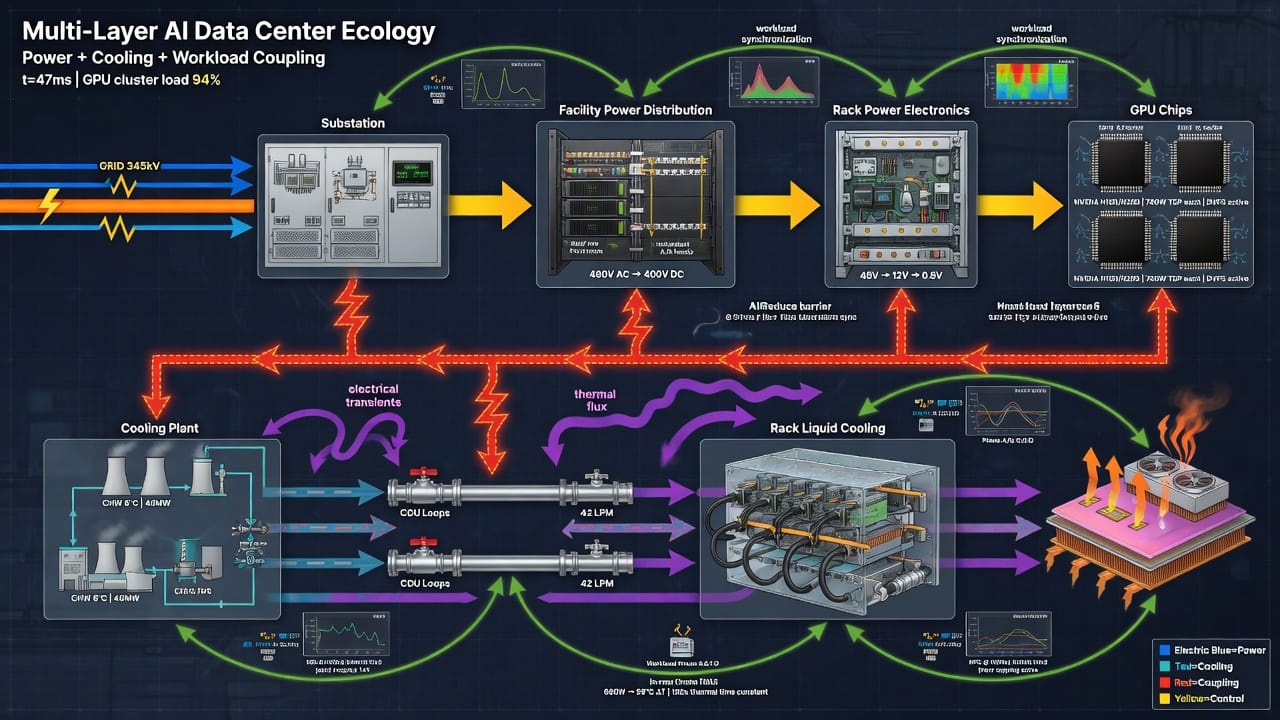
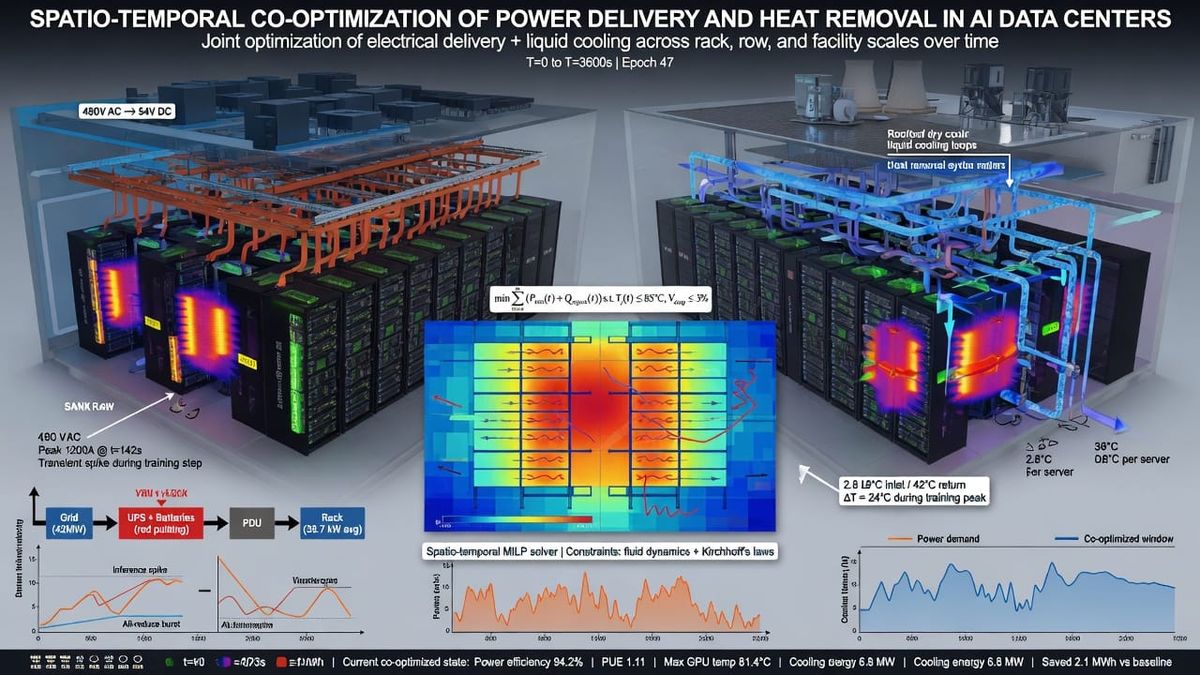
At the top layer, the utility grid delivers bulk power (100s of MW) via high-voltage transmission. At the site level, substations and transformers step down to facility distribution: switchgear, UPS/battery modules, busways, and rack PDUs. Inside each rack, power electronics (PSUs, DC converters) feed the GPUs and other IT loads. Simultaneously, the facility has cooling infrastructure: chillers or cooling towers generate cold water, circulated via pump manifolds (CDUs) into rack- or chip-level cold plates; exhaust heat may feed rear-door exchangers or free-cooling systems. Finally, at the chip level, GPU dies heat-spikes drive heat through heat spreaders, heat pipes, and cold plates into the liquid coolant.
This multi-tier network creates complex interactions. Power flow: sudden current surges from GPUs propagate through busbars and feeders, inducing voltage drops, harmonic distortion, and reactive swings in the facility network. Thermal flow: localized hot spots in a rack lead to uneven coolant temperatures and airflow, which in turn change heat rejection rates and chip junction temps. Temporal coupling: workload scheduling imposes epochs of high compute, during which all GPUs might synchronize and draw peak power, and interleaved lulls. The cooling system lags these swings (thermal inertia of fluid, chiller ramp time), causing overshoots in temperature. Both power and cooling must manage these transients: a spike in GPU power causes a spike in board temperature within seconds, and the rack-level PDU sees an inrush current (high di/dt) that tests breaker and transformer limits.
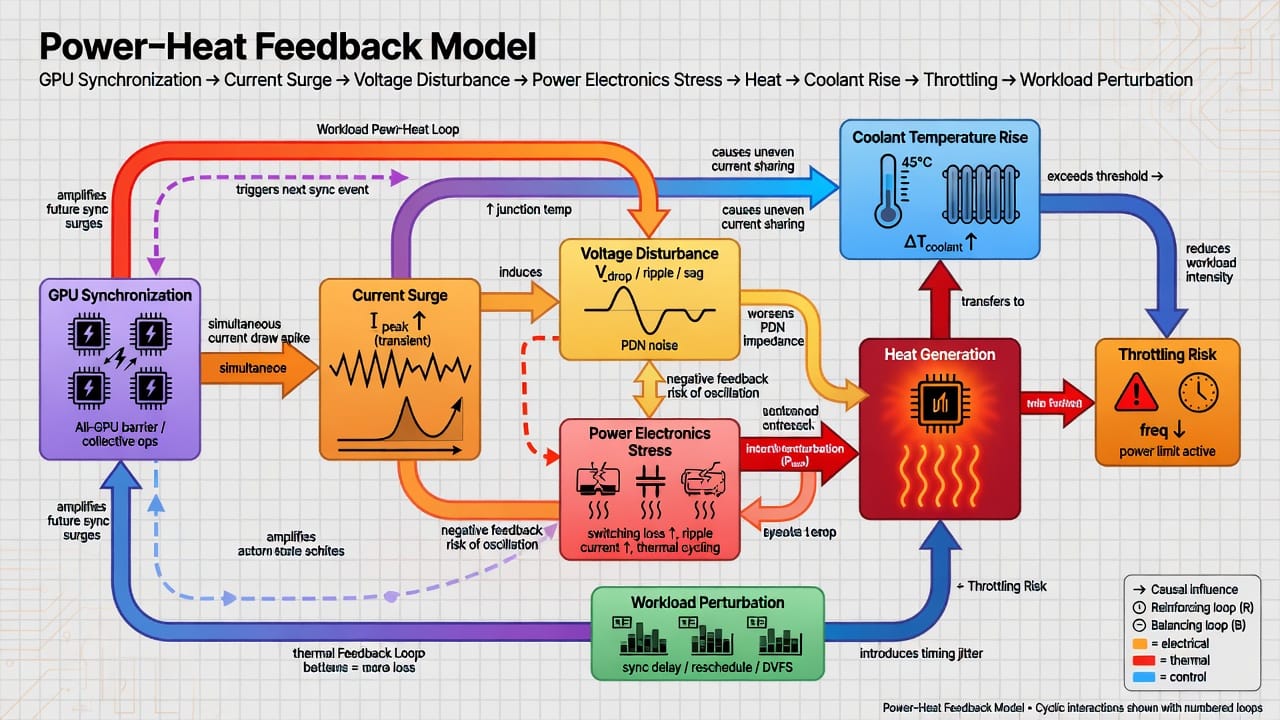
System interactions are thus co-dependent: e.g. a voltage sag reduces GPU clock speeds (soft), which slightly reduces heat output (heat effect), but the fundamental power draw and heat generation remain enormous. Upstream grid impedance and frequency support impact how much power can be drawn fast, while downstream cooling capacity limits how long GPUs can run at peak without throttling. Any model must therefore integrate: (a) electrical transients at multiple scales, (b) thermal dynamics of liquid/air cooling loops, and (c) workload timing patterns that couple them. This is inherently spatio-temporal co-optimization, spanning kilometers (grid) to millimeters (chip junction).
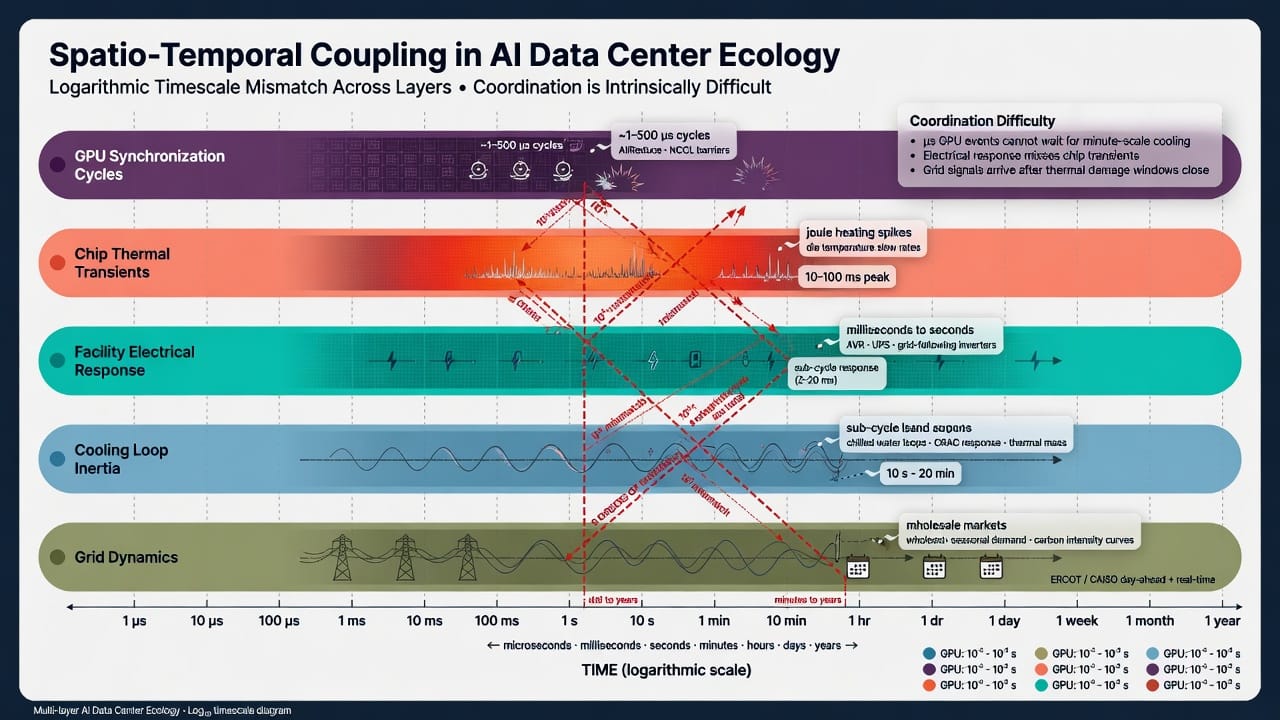
Constraints and Nonlinear Interactions
Many nonlinear scaling laws emerge in this stack. Power vs. cluster size is super-linear: doubling GPUs often requires >2× power due to memory and interconnect overhead. For example, AI memory bandwidth grows rapidly but energy/bit lags, so memory subsystems consume a growing share of power with each generation (an in-depth study of memory power in large AI systems notes that adding servers increases memory power disproportionately, making cooling the true bottleneck). Similarly, cluster throughput scales sub-linearly (Amdahl’s Law and communication latency), so performance per watt degrades with scale. Empirical data shows rack power demands grew tenfold in a few years – from 8–10 kW to routinely 60–120 kW – a clear nonlinear jump.
Electrical limits: Cabling, transformers, and PDUs have finite capacity and inertia. The near-synchronous draws of AI workloads (unlike diversified cloud loads) mean traditional diversity factors vanish. If multiple racks activate GPUs in unison, upstream conductors may see 100% step changes in current within milliseconds. Equipment nominally handles such surges individually, but repeated millions of times per year causes cumulative thermal and mechanical stress. Power quality suffers: rapid load steps induce voltage sags, swells, and harmonics on the AC waveforms. Low-inertia power converters (UPS, rectifiers) dominate the load profile, making the site behave less like a passive resistive load and more like a complex power-electronic system – threatening grid stability (risking voltage and frequency deviations).
Thermal limits: Heat removal is bounded by fluid properties and heat exchange physics. Air-cooling caps out at modest kW/m², so direct liquid cooling is essential. Yet even cold-plate loops have limits: the achievable heat flux scales with coolant temperature difference to the fourth power (Stefan–Boltzmann), meaning only so much heat can be shunted through the cold plate or radiator without exceeding material temperature thresholds. Studies show novel thin-film evaporative designs can triple cooling capacity, yet practical limits remain. Excess heat that escapes cold plates must be removed by room-level coolers or expelled to the environment; these introduce additional delays and inefficiencies. Meanwhile, site resources constrain solutions: water-cooled towers, for instance, consume ~2 million liters per day for a 100 MW facility, so water availability or environmental permits may cap viable cooling power.
Workload dynamics: GPU synchronization means that load patterns often peak concurrently. One AI training iteration can activate hundreds of GPUs in micro-bursts. Such periodic load injection is unlike typical stochastic server workloads. Therefore, temporal “interleaving” strategies used in clouds (smoothing loads over time or nodes) have limited effect. Software-level power smoothing (e.g. injecting dummy tasks to fill idle gaps) can reduce instantaneous swings but at the cost of energy efficiency (maintaining a high power floor wastes energy) and cannot erase the average heat produced. In short, many constraints scale nonlinearly with cluster size and speed: infrastructure must be designed for worst-case peaks, not just average load.
Nonlinear Scaling Behaviors
AI clusters defy the nearly-linear scaling that cloud services enjoy.
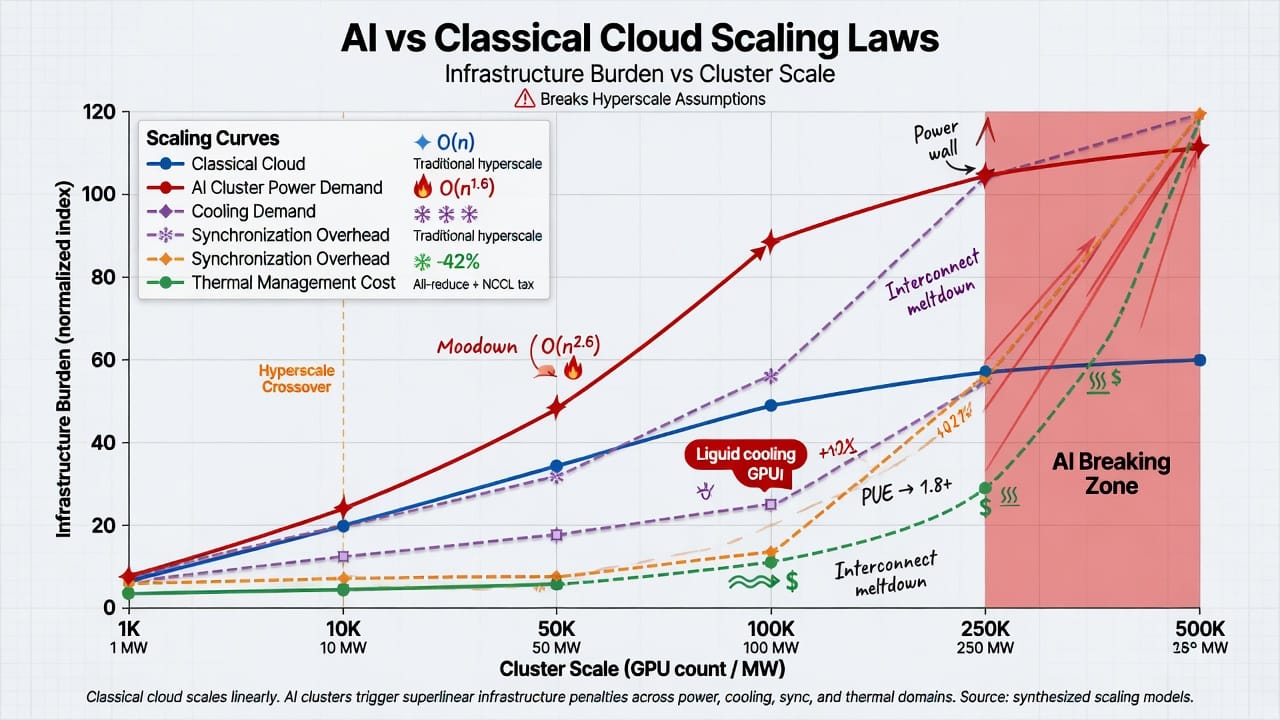
Classical data centers achieve higher efficiency at scale (due to load averaging and virtualization), but AI farms incur diminishing returns. For example, networking overhead (collectives, synchronization) grows super-linearly with GPU count, meaning adding GPUs yields less throughput per watt as systems scale. Memory and I/O bottlenecks also intensify: moving huge model data incurs growing energy and latency that do not scale favorably. Quantitative “AI scaling laws” (model performance vs compute) exist for algorithms, but at the system level we see reverse trends: cost of scale (power, cooling, site infrastructure) rises faster than output.
This is evident in practice. One NVIDIA reference notes that high-end AI rack clusters can almost double their steady state draw during tensor core bursts, leaving no margin. In smaller systems, one could time-multiplex tasks or run at lower turbo frequencies, but at hyperscale the inertia of the facility means any slowdown cascades into revenue loss. Thus cluster operators are forced to overbuild power and cooling so clusters can briefly run “hot”. For example, liquid-cooled NVIDIA GB200 racks have nominal 132 kW ratings but have exhibited transient surges to 150–180 kW – far above planned capacity – because GPUs opportunistically consume extra power during computations. Achieving linear computational scaling (doubling GPUs → doubling throughput) is effectively impossible without also superlinearly increasing energy and cooling budgets.
In sum, AI data centers obey nonlinear scaling laws: infrastructure size must grow faster than compute to maintain reliability. This contrasts classical cloud economics where scale often brings economies (e.g. lowering PUE). Here, even if logic and software are ideal, the physics of electricity and heat demand that facility design be ahead of compute. This mismatch makes simple “add more servers” strategies fail under power and thermal caps.
Failure Modes and Bottlenecks
This co-optimization problem admits several critical failure modes and bottlenecks that no pure software fix can eliminate:
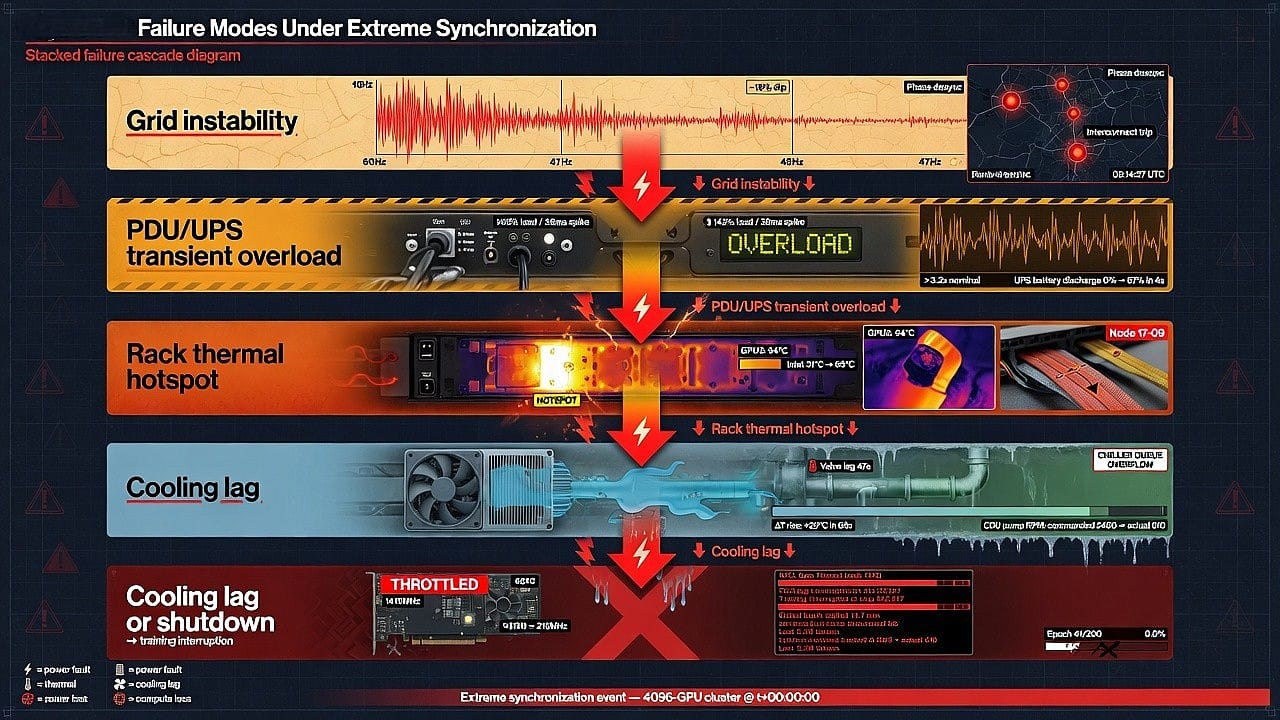
- Electrical equipment stress: Repeated current surges can wear out transformers, PDUs, and switchgear. Uptime Institute warns that power components are not tested for millions of brief overloads. Over time this causes insulation degradation or breaker malfunctions. Excessive harmonics from rapid switching can also overheat transformers. In the worst case, voltage sags may trigger facility shutdowns or damage sensitive electronics.
- Voltage collapse and grid instability: If clusters trip offline suddenly (e.g. due to a fault or overload), the loss of tens of MW can trigger grid frequency swings or cascading outages. Indeed, a 2024 event in Virginia’s data-center corridor (a protection system fault) cut 60 facilities offline, causing major power imbalance. Such events show how tightly coupled large AI loads are to grid stability. Frequency and voltage regulation algorithms in utilities may be overwhelmed by fast swings, since AI loads lack the inertia of traditional synchronous generators.
- Thermal runaway: If heat removal lags, chassis and chip temperatures can climb beyond safe limits. Even briefly exceeding design temps can force GPUs into throttling, dropping performance. Worse, uneven cooling can create hotspots that damage silicon. Some modern GPUs exploit short thermal/energy “headroom” to turbo up, but this amplifies cooling demand. Without sufficient margin, one cannot simply “cool with software”: once the hardware produces heat, physics determines how fast it leaves. Importantly, the laws of thermodynamics (heat flux limits, phase-change stability) set absolute caps on cooling power. No code can transfer heat faster than the cooling medium allows.
- Cooling system failure: Liquid cooling adds single points of failure (pumps, seals, fittings). A leak or pump outage in a cold-plate loop can cause immediate overheating of a rack. Backup schemes (e.g. shutting off hot racks) can protect chips but at cost of throughput and revenue. Moreover, site-level heat rejection (cooling towers, dry coolers) is limited by ambient conditions: on a hot day, even a 100 MW chiller may struggle. In water-scarce regions, one cannot draw infinite water for evaporation. As [35] notes, many new AI sites are in drought-prone areas, making water supply itself a bottleneck.
- Hardware & software mismatch: Techniques like DVFS or power capping can smooth spikes, but they trade off performance. Likewise, deferring workloads (batching or delaying jobs) cannot remove the fundamental energy needed by large models. Put simply, you cannot schedule your way out of a heat problem once peak load is demanded. The MDPI survey observes that raising the power floor (through software) “inevitably leads to increased energy consumption”, highlighting that such fixes are at best partial.
These failure modes are not hypothetical. Reports from industry leaders affirm that power and thermal limits – not compute or space – now cap AI deployment. Many colocation providers already face refusal of permits or grid interconnection delays for new AI halls. This underscores that the remaining barriers are physical and systemic, requiring engineering advances rather than pure software optimization.
Open Research Challenges
We identify several research directions to address this multi-layered problem:
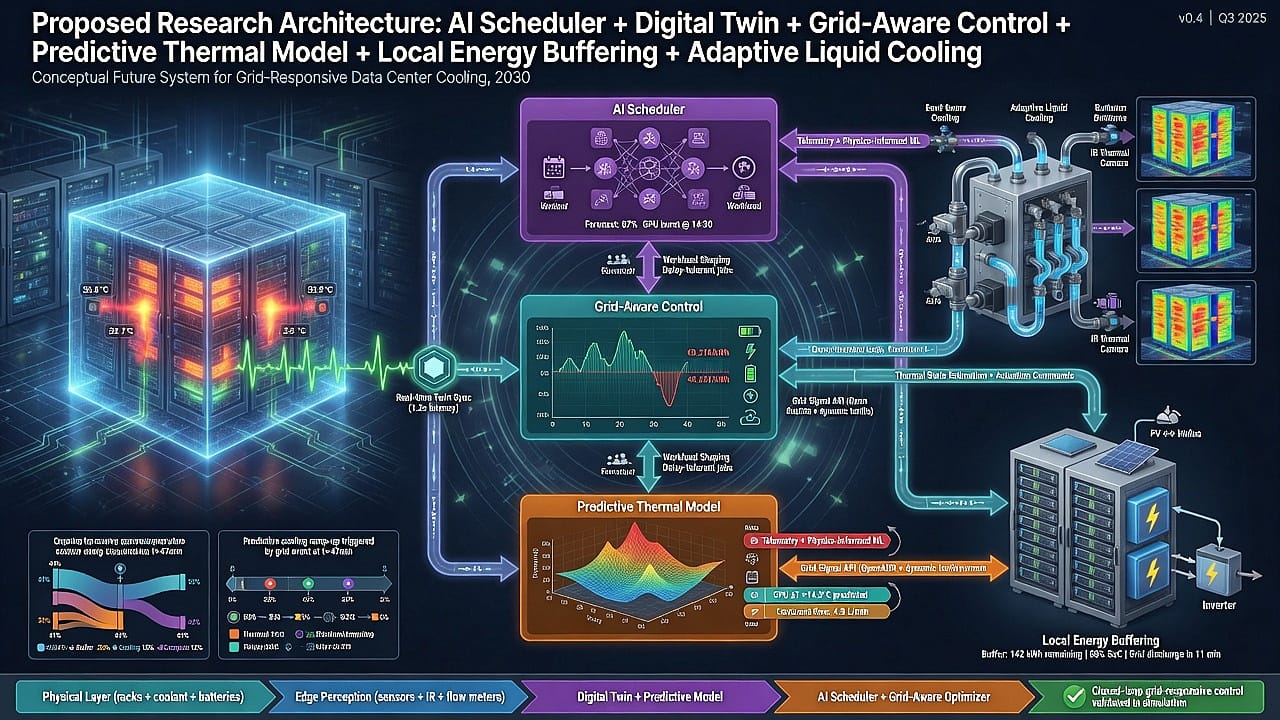
- Holistic modeling and co-simulation. Develop integrated spatio-temporal models that couple the electric grid, on-site power network, and cooling dynamics to AI workload patterns. This includes multi-physics simulation tools (electromagnetic and thermal) that can run across timescales from milliseconds to hours. Digital-twin frameworks could capture real-time interaction of GPU loads with facility systems. Such models would aid design-space exploration, quantifying how changes (e.g. grid impedance, coolant flow rates, scheduling policies) propagate through the ecosystem.
- Smart power electronics and storage. Innovate on hardware front-ends: grid-forming inverters, dynamic phase-shifting transformers, and capacitive or battery buffers at rack-scale. For example, local energy storage (ultracapacitors or flywheels) that absorb peak GPU load surges can isolate the grid from step changes. Grid-forming UPS can actively stabilize local voltage/frequency, reducing disruptions. Research into power-electronic control algorithms that sense GPU cycles and pre-adjust converter settings can mitigate harmonics and transients.
- Adaptive workload scheduling and software-hardware co-design. Design schedulers that are aware of power/thermal context. For instance, distributing compute so that not all GPUs hit peak in lockstep, or shaping AI training waveforms to avoid giant spikes. Co-design chips and software to allow performance throttling in micro-epochs (smoothing load at cost of some latency) could help flatten peaks. Investigate ASIC or accelerator architectures with inherent heat shaping (e.g. side-channel cooling channels or 3D-stacked chips with built-in microfluidics).
- Advanced cooling materials and topologies. Explore next-generation heat removal (beyond standard liquid cooling). Physics-informed designs like branched thin-film evaporators, phase-change materials, or even radiative cooling surfaces could raise the ceiling of heat flux. At scale, implement hybrid cooling (e.g. rack-mounted heat pipes plus economizer systems). Research should quantify trade-offs in efficiency, reliability, and integration cost.
- Grid-aware site design and sustainability. Develop planning tools that jointly optimize power, cooling, and resources. This includes siting AI centers with co-located renewables or waste-heat reuse (district heating). Coupling AI DCs with microgrids that can island or share renewables can ease grid stress. Policy research is also needed: standards for AI infrastructure (e.g. carbon/water constraints), coordinated demand-response programs, and incentives for grid-friendly AI operations.
- Resilient architectures. Build in robustness against worst-case failures: e.g. fail-safe thermal cutoffs, multi-loop redundancy, and advanced monitoring. Machine-learning-based predictive maintenance and anomaly detection can preempt cooling/power subsystem failures. Moreover, integrated cyber-physical defense is needed because AI workloads can be (maliciously or accidentally) modulated to destabilize power. Collaborative protocols between data center controls and utility operators could become a research focus.
These directions form an ambitious, interdisciplinary agenda. They span electrical engineering (power systems, converters), mechanical engineering (thermodynamics, fluid flow), computer science (scheduling, machine learning), and energy policy. Progress will likely require collaboration between academia, industry (hyperscalers, equipment vendors), and utilities to prototype end-to-end solutions.
Conclusion
The spatio-temporal co-optimization of power delivery and heat removal in hyperscale AI data centers epitomizes a multi-layer engineering Gordian knot. It is intractable because it fuses the hardest limits of physics with unpredictable, high-stakes workloads. Our analysis shows that AI clusters do not scale like cloud servers: they inflict super-linear demands on power grids and cooling systems, and they exhibit failure modes that cross domain boundaries. Traditional incremental solutions (software tricks or single-domain fixes) are insufficient. Addressing this crisis will require new paradigms – from grid-edge energy storage and precision cooling technologies to workload orchestration that respects physical constraints. By framing the problem rigorously and citing empirical evidence, we hope to guide the community toward the next generation of solutions. In the words of industry experts, AI scaling is no longer just a chip or algorithm problem, but an infrastructure problem – one we must solve holistically.
Sources: Recent studies and industry reports were consulted throughout (e.g.) to ensure up-to-date, technically detailed insights.



