The Automation Inverse: Why AI Systems Produce Pervasive Errors, Hallucinations, and a Hidden Burden of Human Work
Studies across domains show high AI error rates: hallucinations and incorrect answers remain common, with many benchmarks reporting 40–70% failure. Real‑world use suggests even higher rates, as users frequently must verify or fix AI output.

In the promotional discourse that envelops contemporary artificial intelligence, a promise recurs with liturgical regularity: the technology will liberate humans from toil, reduce cognitive load, and deliver flawless efficiency at scale. Yet the lived experience of countless users—clinicians fact-checking AI‑generated summaries of patient records, lawyers who discover fabricated precedents in briefs drafted by large language models, software developers who must debug insecure code suggested by coding assistants, and journalists who find themselves rewriting machine‑hallucinated quotes—paints a starkly different picture. What users encounter is a landscape of near‑constant errors, plausible yet false statements, and a relentless requirement to verify, correct, and re‑do the very work the system was supposed to automate. The question, “Why do AI systems fail so pervasively that users experience near‑constant errors, hallucinations, and the burden of doing the work the technology claims to automate?” is not a glitch report but an invitation to a deep structural diagnosis. Answering it demands a journey through the historical roots of AI, the foundational assumptions of machine learning, the sociotechnical dynamics of deployment, the competing narratives that frame success and failure, and the epistemic and economic consequences of living with opaque, error‑prone systems.

Historical Foundations: From Symbolic Dreams to Probabilistic Ambiguity
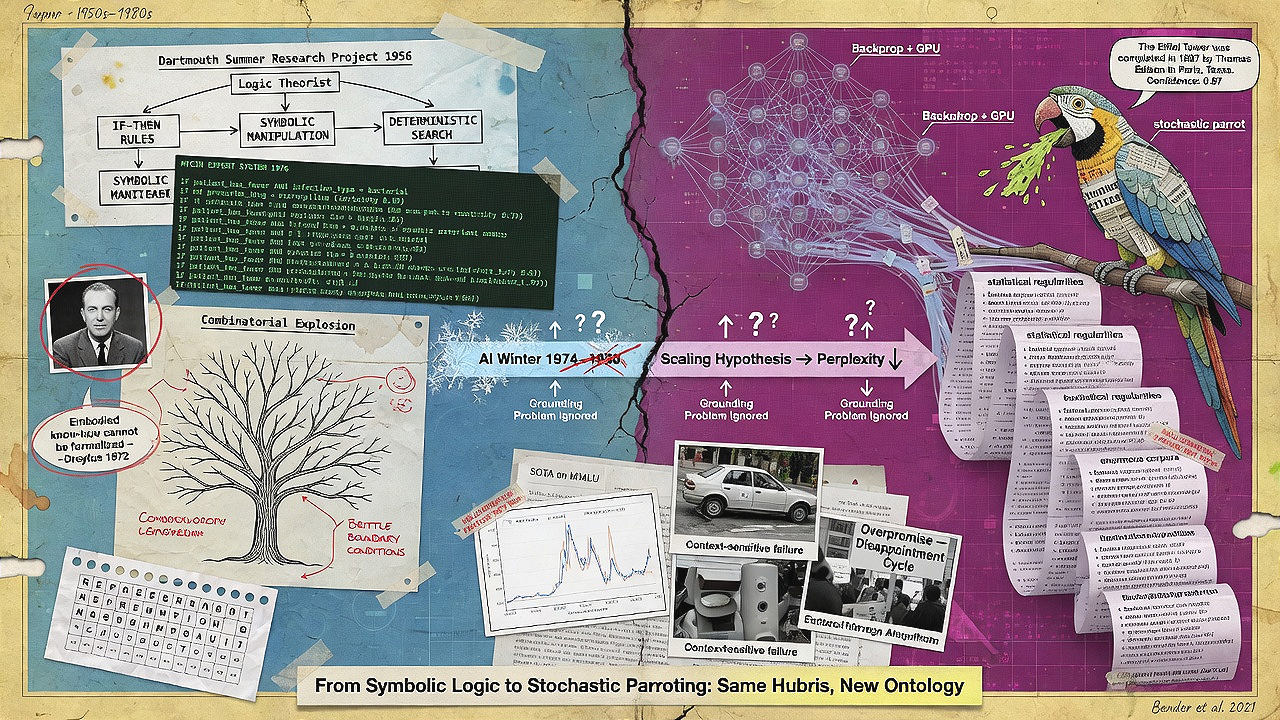
The aspiration to mechanize reasoning began long before the first neural network. Early artificial intelligence, shaped by the Dartmouth Summer Research Project of 1956, inherited a rationalist faith that intelligence could be formalized through symbolic logic, explicit rules, and deterministic search. Systems like the Logic Theorist and later expert systems such as MYCIN encoded domain knowledge as if‑then rules, operating on a representationalist assumption that a sufficient set of symbols and logical operations could mirror expert human judgment. Failure in that paradigm was attributable to incomplete knowledge bases, brittle boundary conditions, or combinatorial explosion—problems deemed solvable through more exhaustive engineering. Even then, critical voices, notably Hubert Dreyfus, argued that human expertise relies on embodied, context‑sensitive, non‑formalizable know‑how, a thesis that the symbolic tradition could never fully accommodate.
The shift toward statistical machine learning and, subsequently, deep neural networks altered the ontology of the system but not the hubris of the promise. Instead of hand‑crafted rules, systems now ingest enormous corpora and extract statistical regularities. The foundational principle is that given a sufficiently large, representative dataset and a flexible function approximator, a model can generalize to new inputs. The backpropagation algorithm and the rise of graphical processing units enabled this vision to scale. Yet this inductive leap from data to pattern contains the seed of pervasive failure. Unlike a logical deduction, a prediction derived from a learned statistical association has no inherent truth condition; it merely reproduces the central tendency of the training distribution, qualified by a confidence score that is itself a learned statistic, not a calibrated measure of epistemic certainty. The “stochastic parrot” metaphor captures this precisely: large language models stitch together plausible sequences of linguistic forms without grounding in experience, intention, or world‑referring semantics (Bender et al., 2021). Hallucination, therefore, is not an anomaly but a direct expression of the model’s design philosophy—a system optimised to maximise the probability of token sequences given a context will, with high frequency, produce sequences that are syntactically coherent, stylistically appropriate, and factually false.
Historical memory further illuminates the cycle of overpromise and disappointment. The AI winters of the 1970s and 1980s resulted precisely from the mismatch between ambitious claims and actual robustness. The current era, despite genuine technical advances, reproduces the pattern: every leap in benchmark performance is heralded as a step toward general intelligence, while the messy, contextual, safety‑critical work of real‑world integration lags far behind. The foundational principle of “scaling”—the observation that larger models and more data reduce perplexity—has been mistaken for a solution to the grounding problem, when it mainly intensifies the model’s ability to mimic patterns, including patterns of error and bias embedded in its training corpus.
Underlying Assumptions and the Architecture of Unreliability
Pervasive failure is not an accidental by‑product; it is the logical consequence of a set of deeply embedded assumptions that are rarely articulated in product launches. The first is the assumption of stationary, independent, and identically distributed data, a condition almost never met outside the clean confines of a benchmark. Real‑world language, visual scenes, and human behavior exhibit distributional shift, long tails, and adversarial noise. When a model trained on Internet text is deployed in a hospital, it encounters clinical shorthand, novel abbreviations, and high‑stakes ambiguity far outside its training distribution. The system then extrapolates confidently, offering a diagnosis with no awareness of its own ignorance. The assumption that a model’s output probability reflects its actual reliability collapses instantly.
A second assumption concerns the sufficiency of aggregate metrics. The AI field evaluates models via accuracy, F1 scores, or perplexity on held‑out test sets drawn from the same distribution as the training data. This practice systematically masks failure modes that are rare in the aggregate but catastrophic in particular cases—the kinds of errors that matter most to individuals. Facial recognition systems that perform with over ninety‑five percent accuracy overall may misclassify Black women at rates many times higher than white men, as the Gender Shades study demonstrated (Buolamwini & Gebru, 2018). The benchmark‑driven evaluation culture thus constructs an illusion of near‑perfect performance while obscuring the differential harms that constitute the user’s experience of constant error.
A third, less examined assumption is that human feedback, collected through reinforcement learning from human preferences or through hand‑crafted safety filters, can adequately align a fundamentally amoral statistical engine with human values and factual reliability. Human raters are themselves subject to fatigue, cultural bias, and inconsistent standards. The resulting alignment is shallow, polishing surface behaviors while leaving deeper tendencies to confabulate untouched. Indeed, alignment techniques that make a model more cautious can increase its refusal to answer legitimate queries, creating a new class of failures where the burden falls on the user to rephrase, coax, or “jailbreak” the system.
The design of AI systems also assumes a compliant, infinitely patient human partner who will adapt to the machine’s quirks. This assumption is encoded in interface design that presents outputs with a veneer of authority—a single authoritative‑sounding answer, a confident tone, no calibrated expression of uncertainty—while pushing the cognitive work of verification entirely onto the user. The burden of doing the work the technology claims to automate arises because the system’s output is not trustworthy by default, yet the user is held accountable for the final outcome. In high‑stakes domains, the user must effectively re‑perform the task: fact‑checking every claim, auditing every line of generated code, cross‑referencing every cited source. The technology thus does not eliminate labor; it shifts its nature from production to surveillance, converting the professional into an unpaid quality‑assurance agent.
Underlying these assumptions are structural biases that shape what data is collected, whose language is deemed standard, and which forms of knowledge are considered authoritative. Training corpora overwhelmingly represent English‑language, digitally mediated, economically privileged perspectives, reinforcing a normative center that systematically misrepresents or erases minoritized communities (Birhane et al., 2022). When a model fails on African American Vernacular English or on non‑Western medical traditions, the failure is not a mere technical glitch but a manifestation of data colonialism. The assumption of neutrality masks a profoundly political distribution of error, where some users pay a much higher cost for the system’s unreliability.

Contested Narratives: Why AI Fails and Who Is Responsible
Interpretations of pervasive failure diverge sharply along disciplinary and ideological lines, and each narrative carries its own assumptions about causality and remedy. The techno‑optimist narrative, advanced by many industry leaders and scaling proponents, frames current errors as temporary growing pains. In this view, hallucinations will be eliminated by larger models, retrieval‑augmented generation, better factuality tuning, and architectural innovations that ground language in external knowledge bases. The burden of verification is a transitional inconvenience; once models become sufficiently capable, users will trust them implicitly. The strength of this perspective lies in its alignment with historical precedent—previous AI weaknesses, such as object recognition errors, have indeed diminished over time—and in its capacity to mobilize investment and talent. Its weakness, however, is that it mistakes symptoms for causes. Improved scaling may reduce the frequency of obvious confabulations, but it cannot solve the fundamental problem of grounding because statistical correlations, no matter how many parameters they encode, do not constitute understanding. The narrative also evades accountability by displacing responsibility onto the future, justifying the deployment of broken systems today in the name of a hypothetical tomorrow.
A competing sociotechnical narrative, rooted in science and technology studies, human‑computer interaction, and critical data studies, locates the source of failure not inside the model but in the decision to deploy it in open‑ended, socially complex settings without robust institutional scaffolding. From this viewpoint, the error is not that a language model occasionally invents a legal citation, but that a legal technology firm sold it to lawyers as a research tool, that law firms adopted it without adequate training, and that a judge considered its output admissible. The failure is one of governance, accountability, and the political economy of automation. The burden users experience is created by the gap between the system’s actual capabilities and the productivity gains promised by its vendors. This perspective is strengthened by a rich body of empirical work on automation surprises in aviation, the “moral crumple zone” in autonomous vehicles, and the paradox that automation often increases, rather than decreases, the cognitive demands on human operators (Elish, 2019). Its weakness is a certain pessimism that can overlook genuine technical improvements and the potential for well‑designed human‑AI collaboration.
A third narrative, which may be called the epistemic erosion thesis, argues that the widespread deployment of fallible AI inflicts harm not only through individual errors but by degrading the shared infrastructures of truth. When search engines integrate AI‑generated summaries that mix fact with confident fiction, when students submit machine‑written essays that professors must painstakingly dissect, and when newsrooms publish algorithmically generated articles without fact‑checking, the collective capacity to distinguish reliable from unreliable information erodes. This perspective, drawing on media studies and information science, emphasizes that the user’s verification burden is not merely an inconvenience but a public‑health‑scale crisis of epistemic hygiene. Its strength is that it connects micro‑level user frustration to macro‑level democratic decay. Its potential weakness is that it can appear to treat AI as a monolithic force, underestimating the diversity of design choices that could mitigate epistemic harm.
Finally, a counter‑narrative from labor studies and the anthropology of work highlights the hidden human labor that makes AI appear functional. The “ghost work” of content moderators, data labellers, and crowdworkers who clean training sets is mirrored by the invisible labor of end‑users who correct, filter, and interpret AI outputs (Gray & Suri, 2019). From this vantage, the system’s failure is a deliberate feature of a business model that externalizes costs onto precarious workers and unpaid consumers. The user who rewrites an AI‑generated report is performing free labor that increases the value of the platform’s data and refines future models, while the platform reaps subscription revenue. The strength of this argument lies in its materialist rigor, revealing the economic incentives that sustain error‑prone systems. Its limitation is a tendency to underplay the genuine technical difficulty of building reliable AI and the non‑cynical motivations of many researchers.

The Broader Implications: Epistemic Erosion, Deskilling, and the Redistribution of Cognitive Labor
Pervasive AI failure reshapes entire knowledge practices. In medicine, the automation of differential diagnosis generation holds the promise of reducing clinician burnout, but when the list includes hallucinated conditions or omits critical rare diseases, the clinician must not only diagnose the patient but also diagnose the machine’s reasoning. This double burden can increase cognitive load and induce automation complacency, where the human begins to trust the machine’s authoritative tone and misses errors, or automation distrust, where the human dismisses useful suggestions and reverts to unaided practice, losing any potential benefit. Over time, the skill of independent diagnostic reasoning atrophies as clinicians become dependent on AI‑generated drafts that they then edit, a form of deskilling that mirrors the erosion of navigational skills following the widespread adoption of GPS. The implication is not that AI should not be used, but that the current pattern of deployment—handing over initial synthesis to an unreliable system and demanding that the human supervise—restructures expertise in ways that are rarely measured, let alone regulated.
The legal domain illustrates a related implication: the responsibility gap. When a judge relies on a flawed risk‑assessment algorithm or a lawyer submits a brief containing fabricated cases generated by a large language model, the resulting injustice lacks a clear locus of accountability. The developer can claim that the system was intended only as an assistive tool, the user can claim to have relied in good faith on a supposedly state‑of‑the‑art technology, and the victim is left without redress. This gap corrodes the principle of due process and generates a climate of diffuse anxiety in which every act of professional judgment is shadowed by the possibility of invisible machine error.
At the organizational level, the pervasive failure of AI reshapes the economics of quality assurance. Companies that adopt AI in customer service, content moderation, or code review often realize that the cost of error detection and correction cancels out the anticipated savings. The labor shifts from performing the primary task to monitoring the machine, but monitoring is itself a demanding cognitive activity, especially for systems that fail intermittently and opaquely. Studies of automated surveillance in air traffic control and process industries have long shown that humans are poorly suited to serve as passive fallback monitors of highly reliable but occasionally erratic automation (Bainbridge, 1983). The contemporary AI landscape repeats this lesson across a far wider array of domains, turning millions of knowledge workers into unwilling participants in a vast, distributed vigilance task.
At the societal scale, the saturation of public discourse with AI‑generated text risks a phenomenon that media ecologists call semantic entropy: the ratio of meaningful, verified communication to plausible‑seeming noise declines. As AI‑generated content contaminates the training sets of future models, a feedback loop of model collapse becomes a tangible threat, where models learn from their own confabulations and the distribution of language drifts away from human‑anchored factuality (Shumailov et al., 2023). The user’s burden of verification thus expands over time, as the baseline trustworthiness of any given text—whether produced by human or machine—decreases.

Ground Truth: Pervasive Failures in Practice
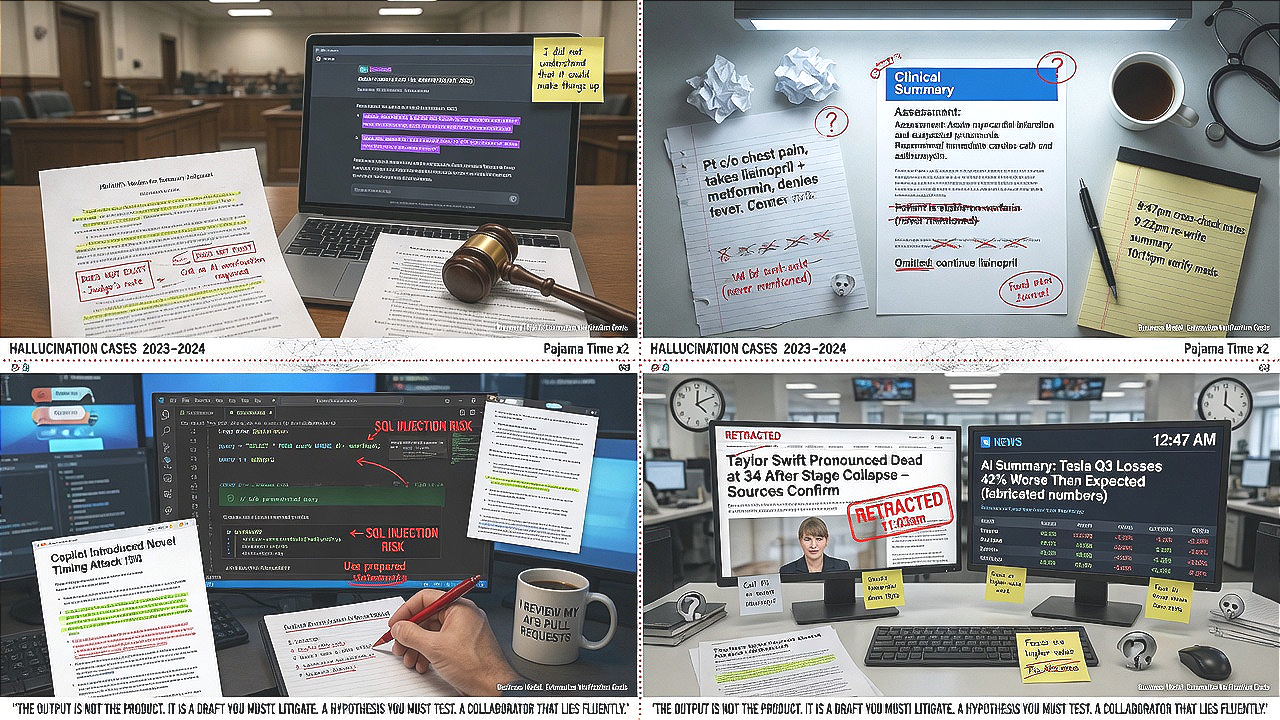
Concrete cases bring the theoretical architecture into sharp relief. In 2023, a legal brief submitted in a federal court in the United States cited multiple judicial decisions that did not exist. The attorney had used a large language model for research and failed to verify the outputs. The judge imposed sanctions, but the episode became emblematic of a systemic vulnerability: the model had not merely summarized existing law incorrectly but had synthesized plausible‑looking citations, complete with plausible docket numbers and plausible reasoning. The attorney’s subsequent explanation—“I did not understand that it could make things up”—underscores the fundamental design flaw: the interface conveyed no meaningful uncertainty signal, and the model’s fluency was mistaken for authority. The burden of legal research was not automated; it was amplified, as the attorney now had to investigate each citation with a suspicion previously reserved for adversary counsel.
In healthcare, a widely publicized study showed that a large language model, when asked to produce a clinical summary of a patient encounter, included diagnoses that were never discussed and omitted critical medications, while phrasing the hallucinated content in the same confident medical prose used for accurate information. Physicians reviewing such summaries reported that the errors were not immediately obvious and required careful cross‑referencing with the original notes, effectively duplicating the documentation effort. The promise of reducing “pajama time”—the hours clinicians spend on electronic health records after hours—was inverted into an additional layer of editorial labour, with potentially lethal consequences if any fabricated detail were acted upon.
Code generation tools exhibit analogous failure patterns. A developer using a copilot‑style assistant may accept a suggestion that introduces a subtle security vulnerability, such as an SQL injection risk or an insecure cryptographic primitive. Because the generated code appears idiomatic and syntactically correct, the developer’s own critical scrutiny is disarmed. Security researchers have demonstrated that models fine‑tuned on large code corpora reproduce vulnerabilities present in their training data and sometimes invent entirely novel ones. The developer becomes a mandatory code reviewer for an unpredictably unreliable collaborator, a shift that reframes the entire activity of programming as supervisory control rather than creative construction.
In high‑stakes news environments, AI‑generated articles have falsely reported celebrity deaths, fabricated financial analyses that briefly moved stock prices, and produced election coverage riddled with invented polling data. The outlets that deployed these systems initially framed them as efficiency gains, allowing human journalists to focus on “higher‑value” work. In practice, the human journalists were forced to issue retractions, rewrite articles under crisis deadlines, and rebuild eroded audience trust—a net increase in labor and reputational cost.
Even in seemingly benign consumer applications, the failure pattern is pervasive. Voice assistants misinterpret commands in ways that require repeated clarification, recommender systems suggest dangerous content to vulnerable users, and AI‑powered search summaries confidently assert falsehoods about basic historical facts. The common thread is that the system’s output functions not as a finished product but as a rough draft that the user must edit, a hypothesis that the user must test, or a claim that the user must litigate against an invisible, unaccountable author. The technology does not automate work; it changes the nature of the work while obfuscating its own unreliability behind a carefully designed interface of omniscience.
The reality of these applications clarifies why the burden persists. The business models that drive AI deployment reward speed, scale, and user engagement, not veracity. A search engine that returns a shimmer of authoritative‑sounding summary keeps the user inside the platform’s ecosystem, whereas a list of links would send them away. The cost of error is externalized onto the user, whose time spent fact‑checking is not priced into the platform’s quarterly earnings. Until economic incentives align with reliability—through liability regimes, professional standards, or user defection—the architecture of pervasive failure will remain profitable.
The Way Forward Is Not More of the Same
Understanding why AI fails so pervasively is not an argument for abandoning the technology but for fundamentally reorienting its design, evaluation, and governance. The insights from information retrieval research, which has spent decades grappling with precision, recall, and user‑centered relevance, must be integrated with the evaluation of generative systems. Metrics that measure factual consistency against ground truth corpora, calibration of confidence, and the user’s verification time are all technically feasible yet remain marginal in a field still mesmerized by leaderboard climbing. Human‑computer interaction research offers rich frameworks—such as seamful design, which exposes the boundaries of a system’s competence, and uncertainty visualization, which communicates the model’s own estimate of its ignorance—that could transform the user’s role from unwitting error‑detector to informed collaborator. Algorithmic auditing, pioneered by researchers in accountability and fairness, needs to become as routine a part of the AI lifecycle as unit testing is in software engineering, with independent third‑party assessments of error distributions across demographic and contextual strata.
Policymakers, professional associations, and standards bodies must address the responsibility gap by establishing clear duties of care for deployers of AI in high‑stakes settings. A model that generates plausible medical advice cannot be treated as a neutral tool akin to a spellchecker; it is a decision‑support device with a known failure mode, and its deployment should carry legal obligations analogous to those for medical devices. Professional licensing bodies can require that practitioners demonstrate competence in verifying AI outputs before using them in practice, reframing the burden not as an invisible tax on the user but as a formal competency.
On a deeper level, the pursuit of artificial intelligence must recover a respect for the richness of human cognition that it has systematically stripped away. Human reasoning is not merely next‑token prediction on a biological neural network; it involves metacognition, the ability to recognize the limits of one’s own knowledge and to act accordingly. Building a machine that says “I don’t know” clearly and usefully would be a more profound engineering achievement than yet another model that achieves a new state‑of‑the‑art on a decontextualized benchmark. Until the field values calibrated humility as much as fluency, the user will remain locked in the automation inverse: working harder, under greater uncertainty, to sustain the fiction that the machine is working at all.
References
Bainbridge, L. (1983). Ironies of automation. Automatica, *19*(6), 775–779.
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–623. ACM.
Birhane, A., Kalluri, P., Card, D., Agnew, W., Dotan, R., & Bao, M. (2022). The values encoded in machine learning research. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 173–184. ACM.
Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. Proceedings of the 1st Conference on Fairness, Accountability and Transparency, 77–91. PMLR.
Elish, M. C. (2019). Moral crumple zones: Cautionary tales in human-robot interaction. Engaging Science, Technology, and Society, *5*, 40–60.
Gray, M. L., & Suri, S. (2019). Ghost work: How to stop Silicon Valley from building a new global underclass. Houghton Mifflin Harcourt.
Shumailov, I., Shumaylov, Z., Zhao, Y., Gal, Y., Papernot, N., & Anderson, R. (2023). The curse of recursion: Training on generated data makes models forget. arXiv preprint arXiv:2305.17493.



